FreeOCR.net 2.1
Skenování a převod obrázků na text
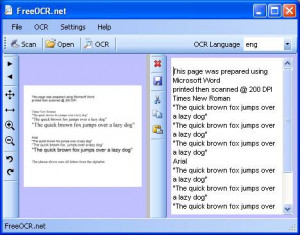
Problematika skenování prostého textu sebou nese jednu velikou nevýhodu - výsledný naskenovaný text lze totiž standardně uložit pouze do obrazového formátu (BMP, JPEG, TIFF atd.). Tudíž případné následné úpravy v textu jsou téměř nereálné.
Naštěstí existují programy typu OCR, jež umí převést naskenovaný text do klasické textové podoby - jedním z nich je i FreeOCR.net. Program podporuje řadu znakových sad, včetně Unicode (UTF-8) odpadá tím problematika nezobrazení některých méně obvyklých znaků.
Naštěstí existují programy typu OCR, jež umí převést naskenovaný text do klasické textové podoby - jedním z nich je i FreeOCR.net. Program podporuje řadu znakových sad, včetně Unicode (UTF-8) odpadá tím problematika nezobrazení některých méně obvyklých znaků.
Celkové hodnocení
Sdílet program
Souhrnné informace o FreeOCR.net
-
Licence
-
Verze programu
2.1 -
Autor
-
Potřeba instalace
ano -
Domovská stránka
-
Velikost souboru
2 MB -
Operační systém
- Windows XP,
- Windows 2000,
- Windows Vista
-
Jazyk
- Angličtina
-
Staženo
28 444× celkem
4× tento měsíc -
Poslední aktualizace
3. 12. 2007


















