Hashovací funkce, algoritmus, výtah, miniatura, otisk, fingerprint či krátce hash. Pod tímto názvem se z hlediska koncového uživatele vlastně neskrývá nic moc složitého. Jednoduše princip je asi tento: vezmeme jakýkoli vstup (text, obrázek, celý soubor), proženeme ho hashovací funkcí (viz obrázek níže) a vyjde nám zdánlivě nesmyslné dlouhé číslo (otisk) složené z číslic a písmen. Hashe mají však v informatice široké využití, a to i proto, že mají (resp. mají mít) tyto vlastnosti:
- jakékoliv množství vstupních dat poskytuje u jednoho typu hashe stejně dlouhý výstup (otisk),
- malou změnou vstupních dat dosáhneme velké změny na výstupu (tj. výsledný otisk se od původního zásadně na první pohled liší),
- z hashe je prakticky nemožné rekonstruovat původní text zprávy (což je rozdíl oproti klasickému šifrování),
- v praxi je vysoce nepravděpodobné, že dvěma různým zprávám odpovídá stejný hash, jinými slovy pomocí hashe lze v praxi identifikovat právě jednu zprávu (ověřit její správnost).
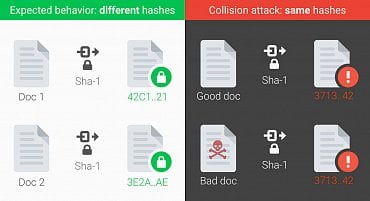
Schéma kolize v SHA-1
SHA-1 pro obrázek výše je např. 03ecb4744b11c9bf6eb5c3c24fcbbfdefb0d32d3. Změní-li se byť jediný bit (zkuste si obrázek otevřít v editoru a znovu uložit), vyjde zcela odlišné číslo. To je právě jedna z vlastnost hashovacích funkcí, která musí fungovat. Google v praxi dokázal, že u SHA-1 mohou mít dva různé vstupy stejný otisk, což celý algoritmus degraduje. Protože další vlastnotí hashovacích funkcí je, že pro jakkoli velký vstup vyjde vždy stejně dlouhý otisk, využívají se otisky i pro hledání stejných položek v databázích (pro jakkoli velký vstup vyjde u SHA-1 jen 40 šestnáctkových číslic) apod. Dalším problémem je hlavně bezpečnost certifikátů. Jednoduše řečeno, SHA-1 již v ostrém nasazení nemá co dělat a prohlížeče v letošním roce přestanou podporovat jím podepsané certifikáty (u HTTPS). V praxi se ale již většinou používají algoritmy z rodiny SHA-2 (např. SHA-256).
Zdroj: googleblog.com