
ABBYY FineReader je nástroj s širokými možnostmi využití. Primárně se jedná o (ne)standardní softwarový nástroj pro rozpoznávání textu z grafické předlohy, avšak na zcela profesionální úrovni. Aplikace je schopna zpracovat různé typy grafických podkladů od naskenovaných dokumentů až po soubory ve formátu PDF. Vzhledem k faktu, že jedná o moderní a robustní nástroj s dlouhou historií vývoje, není vzhled předlohy rozhodně omezen pouze na prostý a souvislý text, ale vestavěné OCR algoritmy jsou schopny celkem bez problémů zpracovat i dokumenty s bohatou grafickou úpravou.

Výchozí dialog po spuštění aplikace
Poslední verze navíc přináší mnohá zlepšení v podobě lepšího výkonu nebo, a to především, rozšíření funkcí o zcela nové nástroje a možnosti. Řada původních vlastností rovněž doznala různě velkých změn. Nezanedbatelným pozitivním atributem celé aplikace je přehledné rozhraní a z toho vyplývající jednoduchá a rychlá obsluha. To zaručuje i přes značnou sofistikovanost programu a velký počet funkci zachování dobré úrovně efektivity práce.
Přehled základních funkcí
Na naprostém začátku stojíme před rozhodnutím, jakým způsobem aplikaci předložíme požadovaný dokument. Za tímto účelem nám ABBYY FineReader nabízí hned několik možností.
Podporované vstupní formáty
Jako první z nich můžeme jednoznačně jmenovat využití klasického scanneru pro zdigitalizování tištěných dokumentů. Pro daný úkon program disponuje přehledným ovládacím rozhraním, skrze něž je možné scanner pohodlně nastavit a zvolit rozsáhlé možnosti parametrů pro zajištění co nejlepší kvality samotného vstupu. Další možností, jak zdigitalizovat fyzický dokument, je digitální fotoaparát. Tato metoda s sebou však přináší oproti minulé určitá specifika, která nejsou pro následné zpracování OCR nástroji příliš optimální. ABBYY FineReader disponuje funkcemi, které jsou určeny speciálně pro tuto variantu, a tak není problém přímo v rámci aplikace využít pokročilé automatizované nástroje pro potřebnou úpravu fotografií jako je úprava ISO, zešikmení, perspektivní zkreslení a řada dalších funkcí, jinak typických pro specializované bitmapové editory.
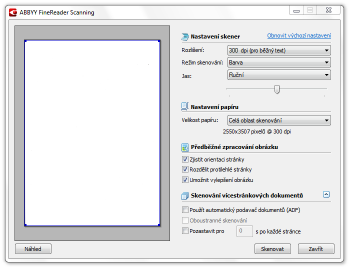
Ovládací panel scanování
Jako vstup pro OCR můžeme taktéž použít širokou škálu formátů nejen obrazových souborů. Jmenovitě se jedná o BMP, DIB, RLE, PCX, DCX, JPEG, JPEG 2000, JBIG2, PNG, TIFF, PDF, XPS, DjVu, GIF a WDP.
Zpracování dokumentu
V této fázi se dostává ke slovu opět jedna z velmi silných stránek aplikace. Zcela pochopitelně je největší důraz kladem především na správnost převodu informace z obrazové do textové podoby. Za tímto účelem disponuje program velmi pokročilými algoritmy, které berou v potaz i obsah rozsáhlého integrovaného slovníku, jenž je navíc dostupný pro obrovské množství jazyků, počínaje arabštinou a konče např. vietnamštinou. Pakliže bychom dostali jako výsledek zpracovaného dokumentu pouze neformátovaný text, byla by práce ve většině případů hotova maximálně z poloviny. Zbytek by připadl již na manuální práci uživatele za využití lidské inteligence.
Oním zbytkem je míněno zachování logické struktury dokumentu, které je v digitálním světě mimořádně důležité pro umožnění vyhledávání a třídění informací. Logická struktura je u fyzických dokumentů vyznačena prostřednictvím grafických elementů, avšak zde se dostáváme k problému, že jeden a ten samý strukturní prvek může být v různých dokumentech zobrazen odlišně. S těmito záležitostmi se umí ABBYY FineReader rovněž vyrovnat obstojně, a tak pro něj nebývá problémem správně rozpoznat např. seznamy, nadpisy, záhlaví a zápatí, odrážky, číslování a podobné prvky. Rozvržení stránky na sloupce, formátované tabulky a přiřazení správného fontu jsou samozřejmosti.
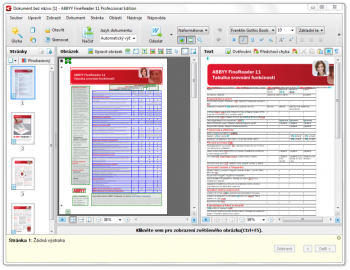
Analýza a zpracování dokumentu
Toto je možné na základě patentované technologie ADRT společnosti ABBYY, jež byla vytvořena k zachování logické struktury dokumentu. Jedná se o tzv. adaptivní technologii rozeznávání dokumentů. Právě ta má „na svědomí“ nejen uchování stylu a rozvržení prvků ve zpracovaném dokumentu, ale i jejich „smyslu“. To v konečném důsledku ulehčuje i případnou editaci digitalizovaných materiálů.
Možnosti výstupu
Po úspěšném zpracování obrazového dokumentu se dostáváme k rozhodnutí, do jakého formátu výsledný dokument exportovat. Opět máme na výběr z velkého počtu možností. Jako základ můžeme zmínit standardní formáty dokumentů typu DOCX, XLSX, ODT apod. Zvolit je pochopitelně možné i formát PDF, který zajistí snadnou přenositelnost napříč platformami při zachování požadovaného vzhledu.
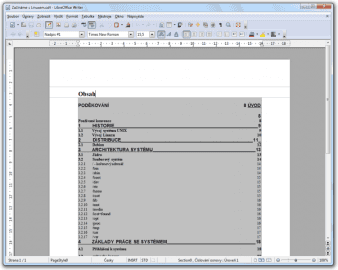
Převedený dokument ve formátu ODT
V neposlední řadě zvládá ABBYY i export do několika nejrozšířenějších formátů elektronických knih včetně odeslání zpracovaného dokumentu na účet Kindle. Myšleno bylo též na webovou publikaci, a tak nechybí formát HTML s podporou kapitol, které jsou volitelně ukládány do samostatných souborů a provázány odkazy.
Závěr
Popsat veškeré vlastnosti či dovednosti recenzované aplikace by bylo nad možnsoti rozsahu jednoho článku. Aplikaci je možno vskutku zařadit mezi naprostou špičku v profesionálním OCR zpracování dokumentů a díky svým možnostem, jako kupříkladu hromadné zpracování dokumentů prostřednictvím FTP, elektronické pošty a podpory práce ve skupině, najde uplatnění i ve velkých firmách. Za tímto účelem je k dispozici i několik různých licencí, které by měly odrážet optimální míru funkcionality pro jednotlivé skupiny zákazníků.

Produkt ABBYY FineReader 11 můžete výhodně zakoupit v našem obchodě SW.CZ